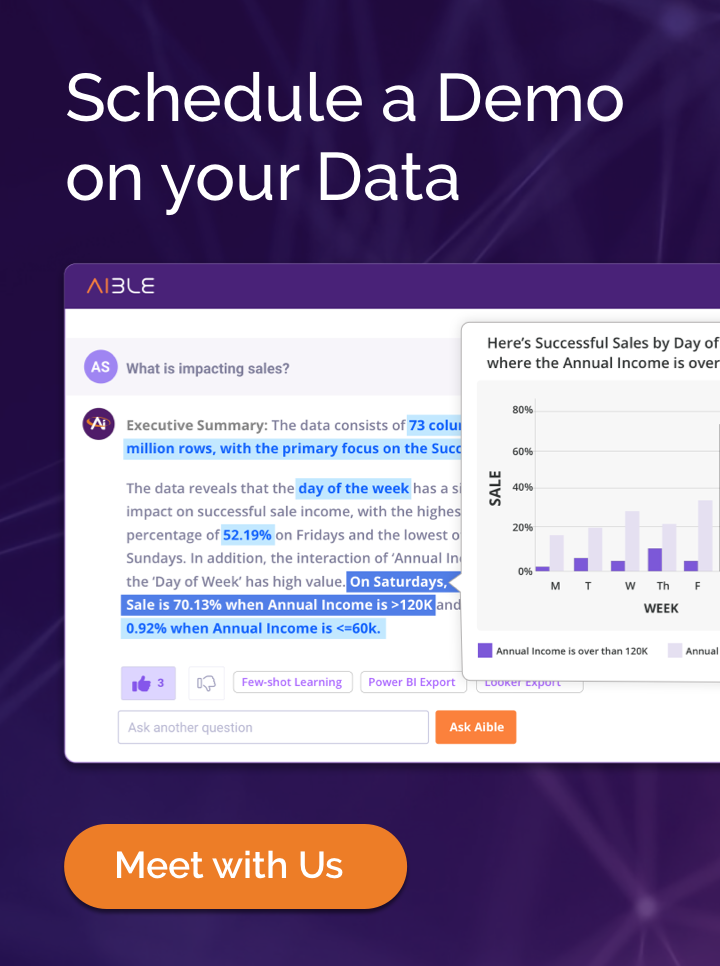




Generative AI Dashboards
Aible GenAI Dashboards combine Natural Language Query (NLQ) with dashboards to address the inflexibility issues with traditional dashboards. Users can easily start with a familiar dashboard with multiple examples of NLQ questions and responses and then can just copy and edit those questions to ask their own. Aible also addresses the key problem of NLQ solutions – what questions should we ask? Knowing the right question to ask is the biggest part of the problem.
.png)
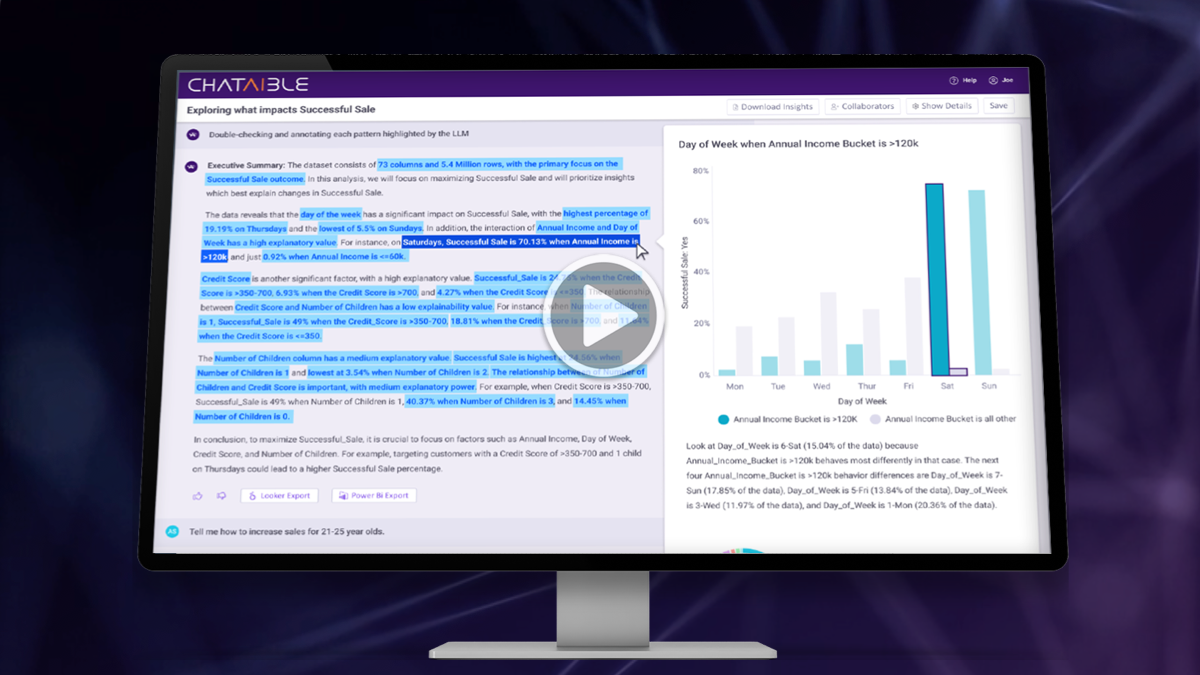
Hallucination checks for Natural Language Queries (NLQ)
Aible addresses a key problem with GenAI NLQ – making sure it is answering the right questions accurately. Other solutions use a single model to translate the users’ questions into Structured Query Language (SQL) and then execute that SQL to produce the answer. They very helpfully provide the SQL to the user so that they can check that the SQL looks correct.
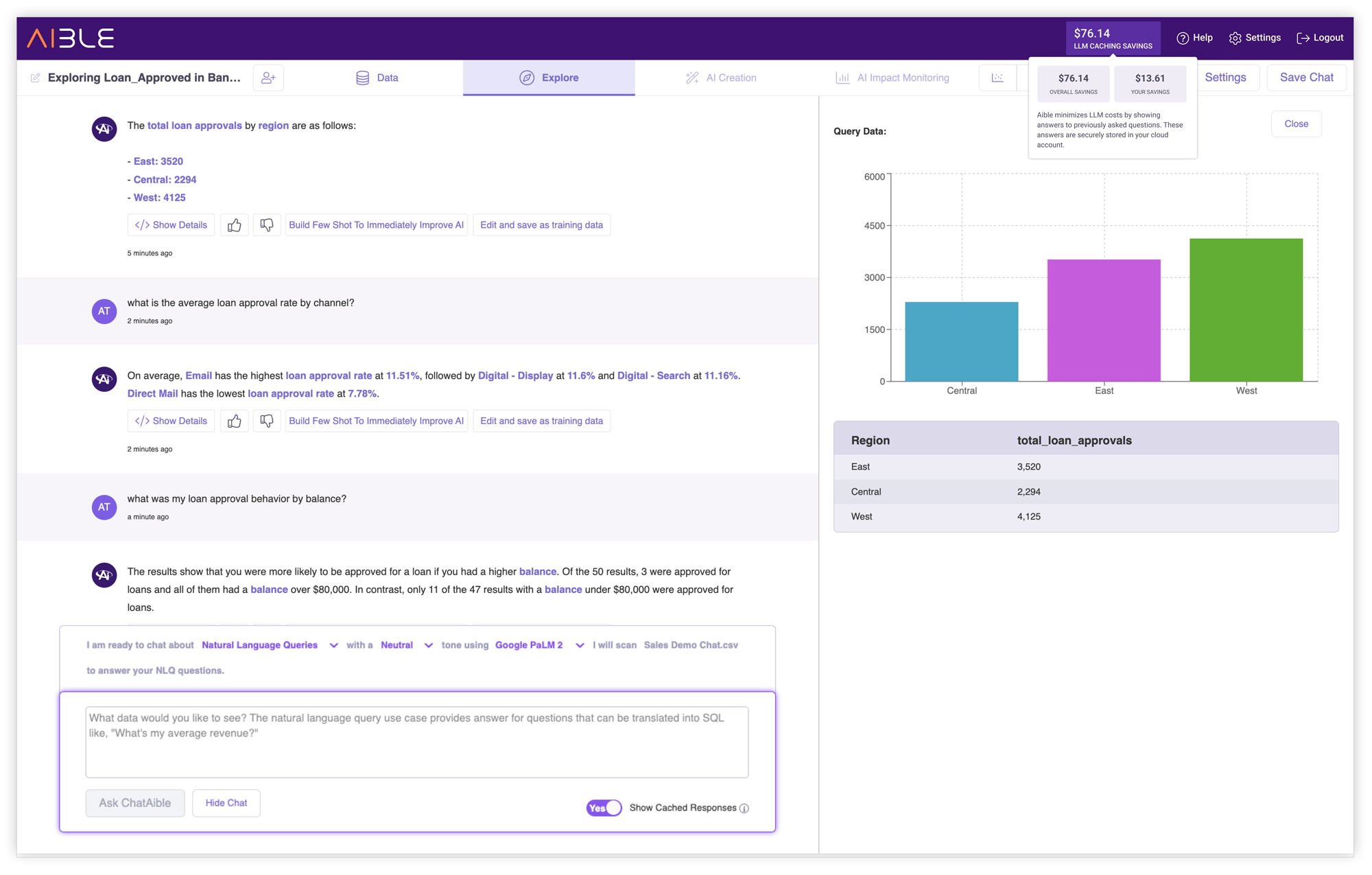
Caching for Natural Language Queries (NLQ)
In our analysis of NLQ questions at larger organizations, we found that there was significant overlap in the user questions. Once we looked at the underlying themes of the questions – because there are many ways to ask essentially the same question – there was even more overlap. In traditional approaches, when such redundant questions are asked, you incur the GenAI model response cost as well as the cost of querying the underlying data.
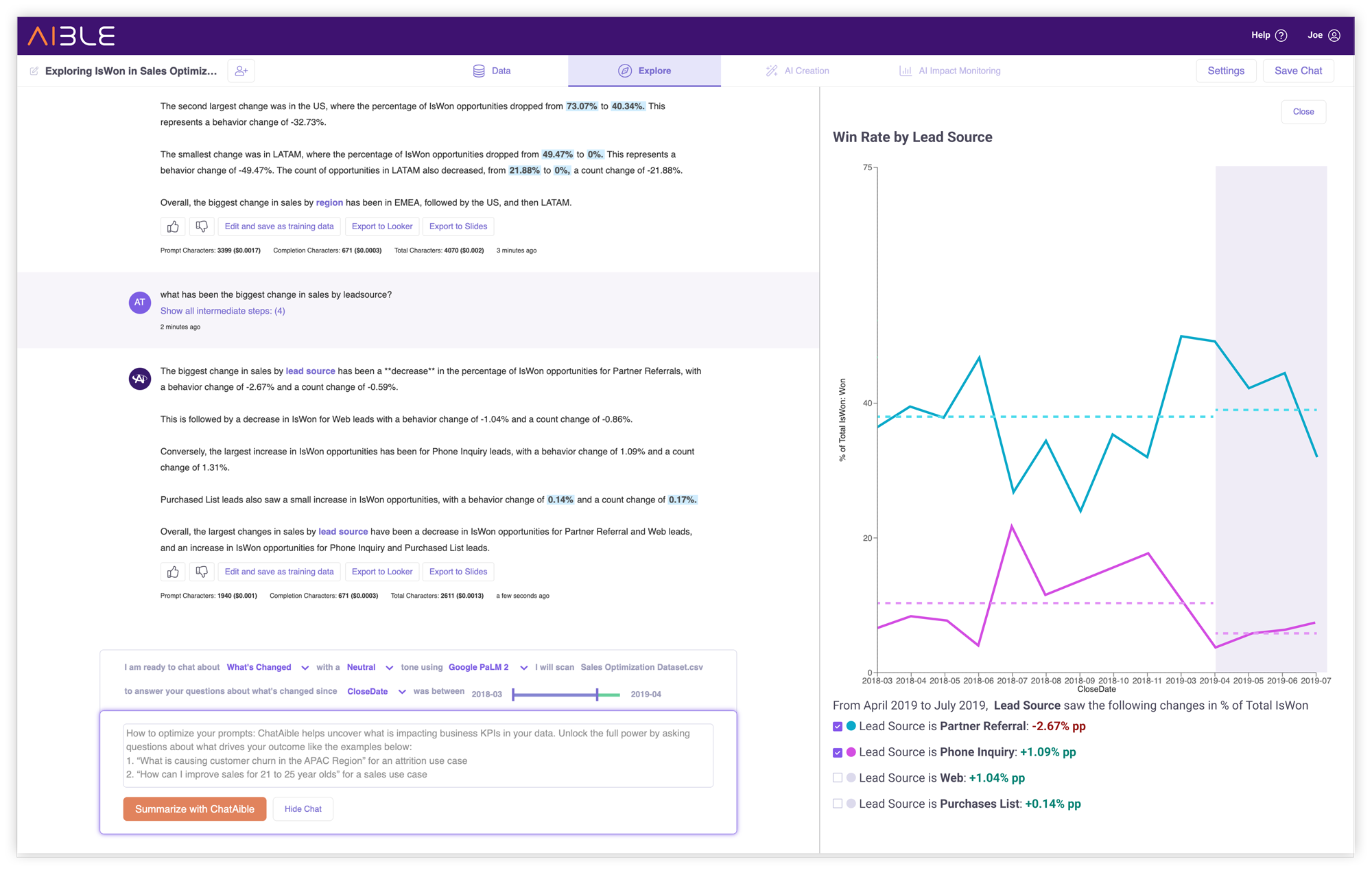
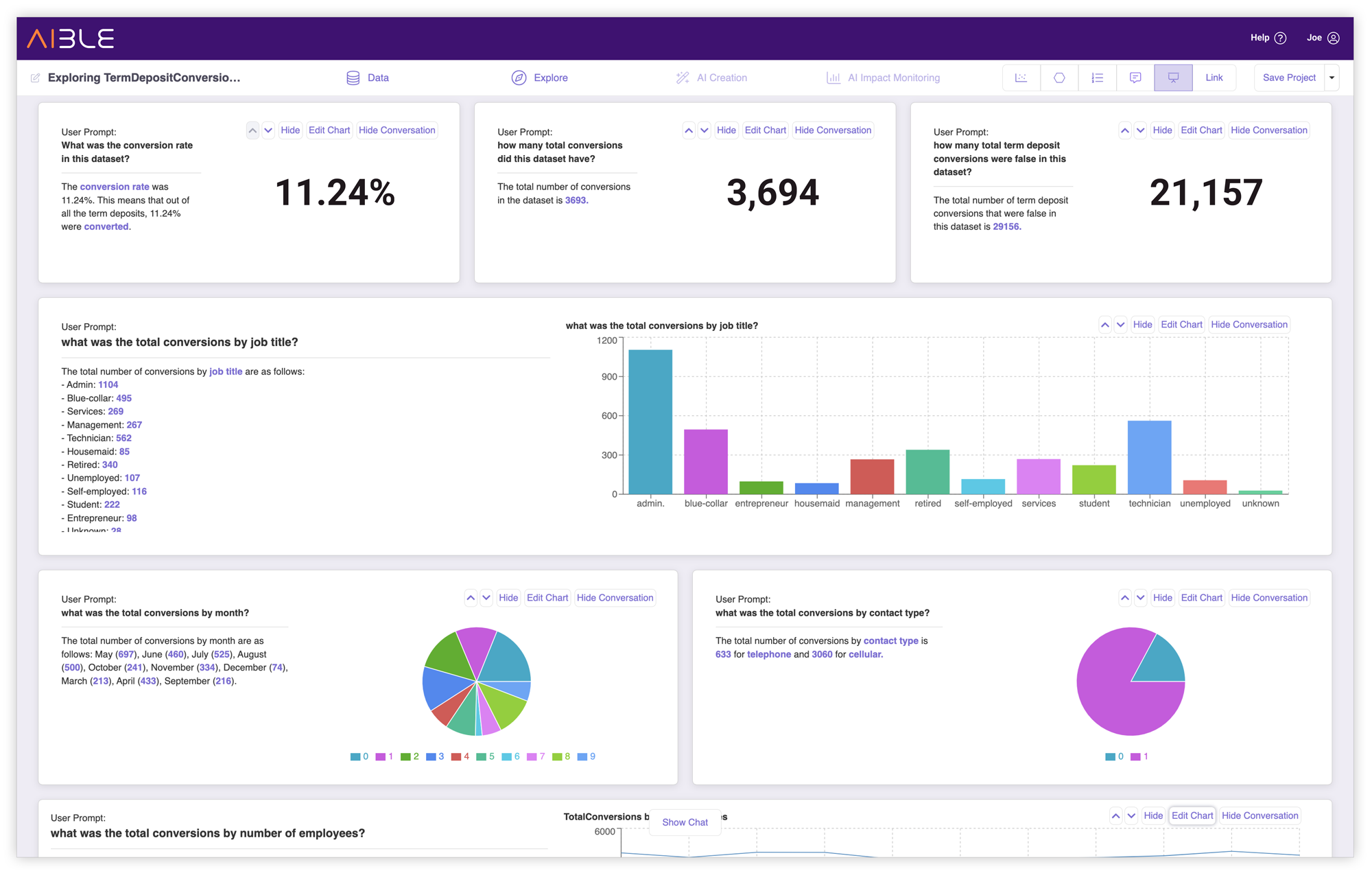
What’s Changed Analysis
Business users regularly want to understand how and why their business has changed between two time periods - last month to this month, last year to this year, etc. Now Aible automatically performs What’s Changed Analysis to swiftly pinpoint and analyze the cause of significant changes in Key Performance Indicators (KPIs) and presents them via a simple chat interface.
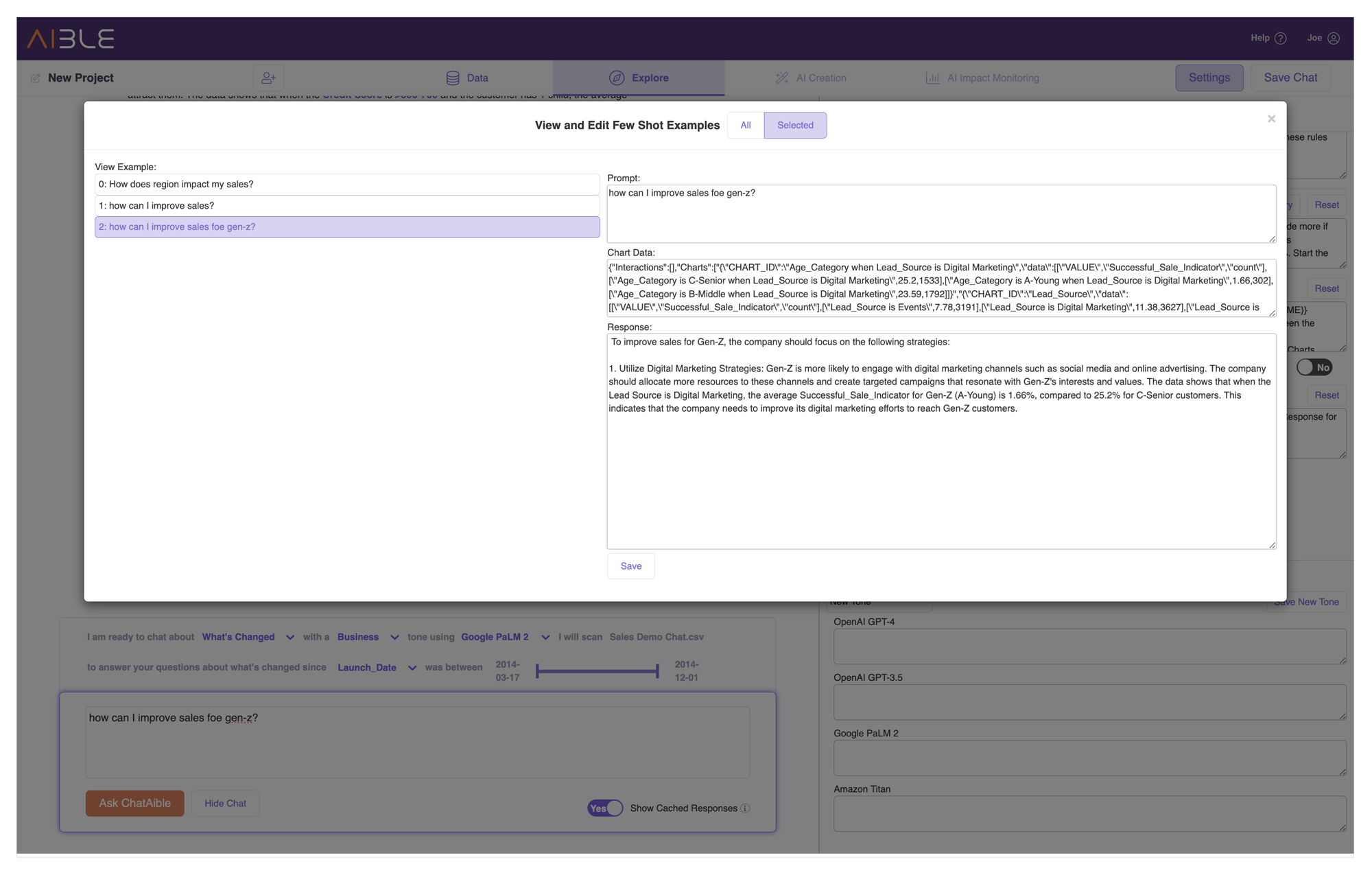
Automated Few Shot Learning
User feedback is extremely important for improving GenAI models. Unfortunately most business users are not used to providing feedback and can offer contradictory and even misleading feedback. Data Scientists often incorporate thousands of feedback over months to retrain the models and thus can’t trace the results of the retrained model back to individual user feedback. Thus, there is no immediate feedback loop in generative AI today.
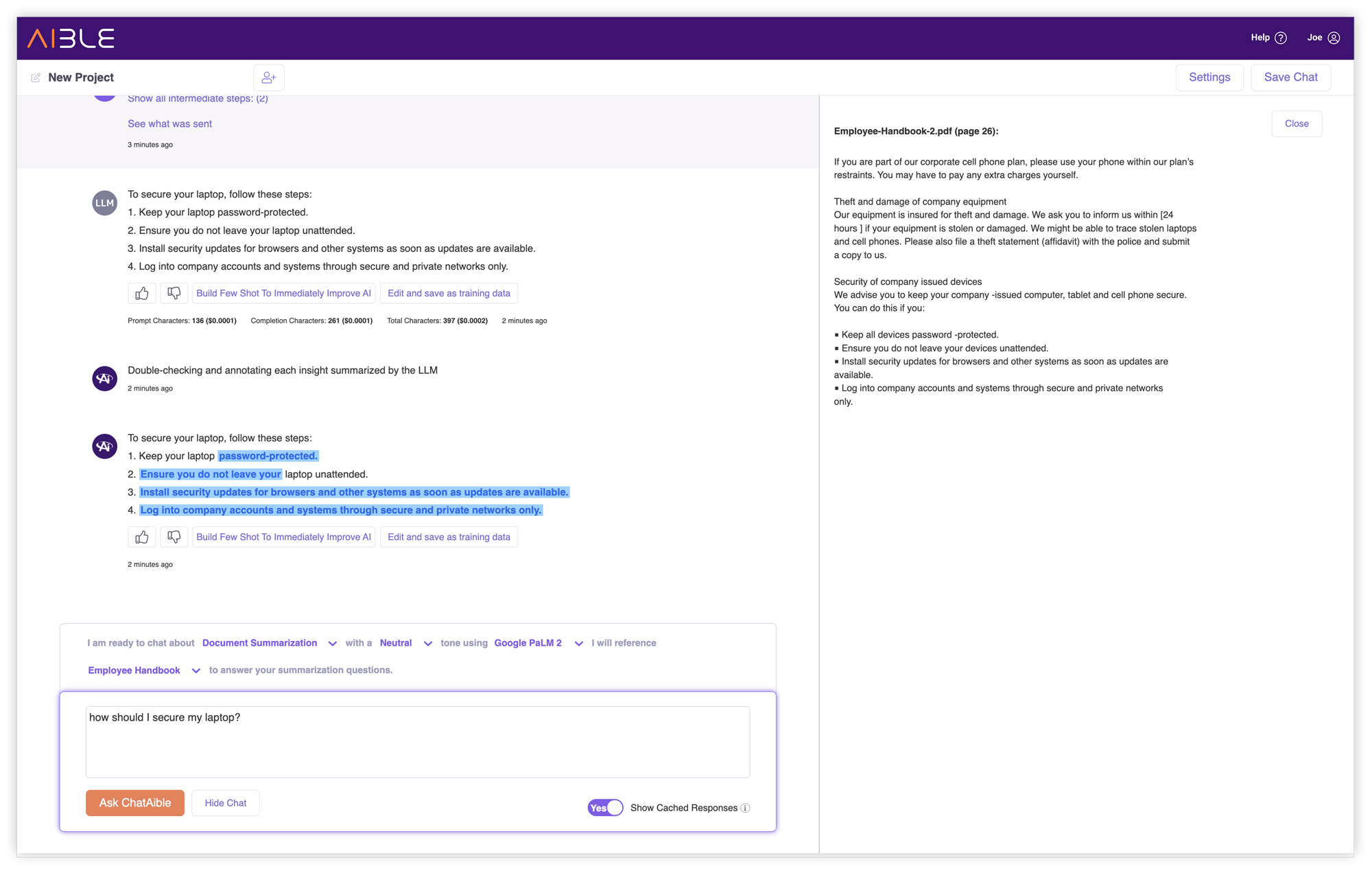
Unstructured Data Hallucination Double Check
Aible’s “If It’s Blue, It’s True” automated hallucination double-checking for structured data has consistently been one of our most popular genAI features. We now brought the same capability to unstructured data. Aible automatically parses the output of the genAI to detect which sections were based on enterprise documents and which were ‘made up’ by the GenAI.
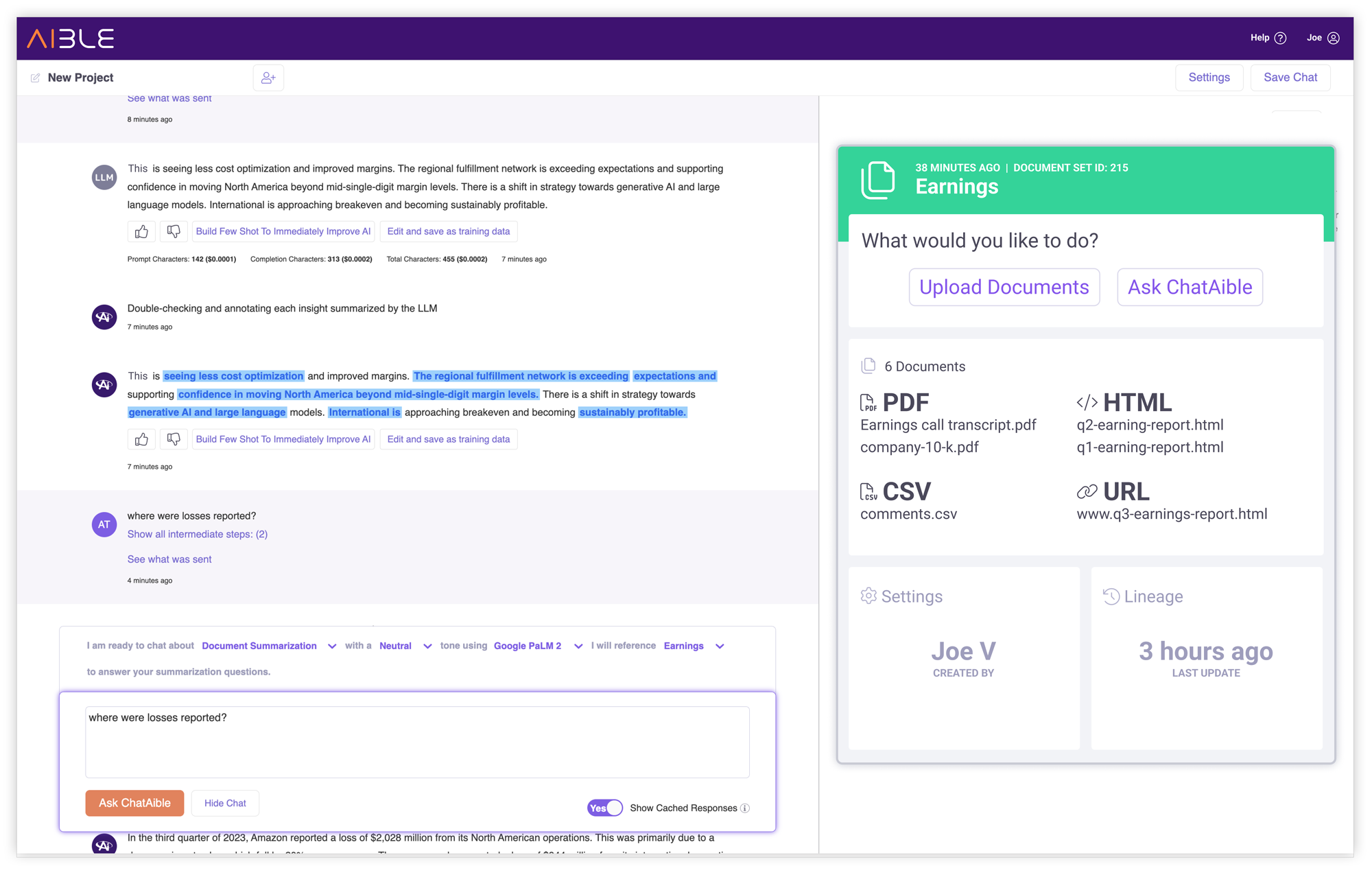
Blended datasets - HTMLS/PDF etc.
Aible can now be leveraged for GenAI use cases that span insights in multiple unstructured document sets in different formats. Multiple documents of different types - for example PDF, CSV, HTML, URL, Markdown and more - can be included in the same document set. Users can then ask questions that span all of the disparate document types.
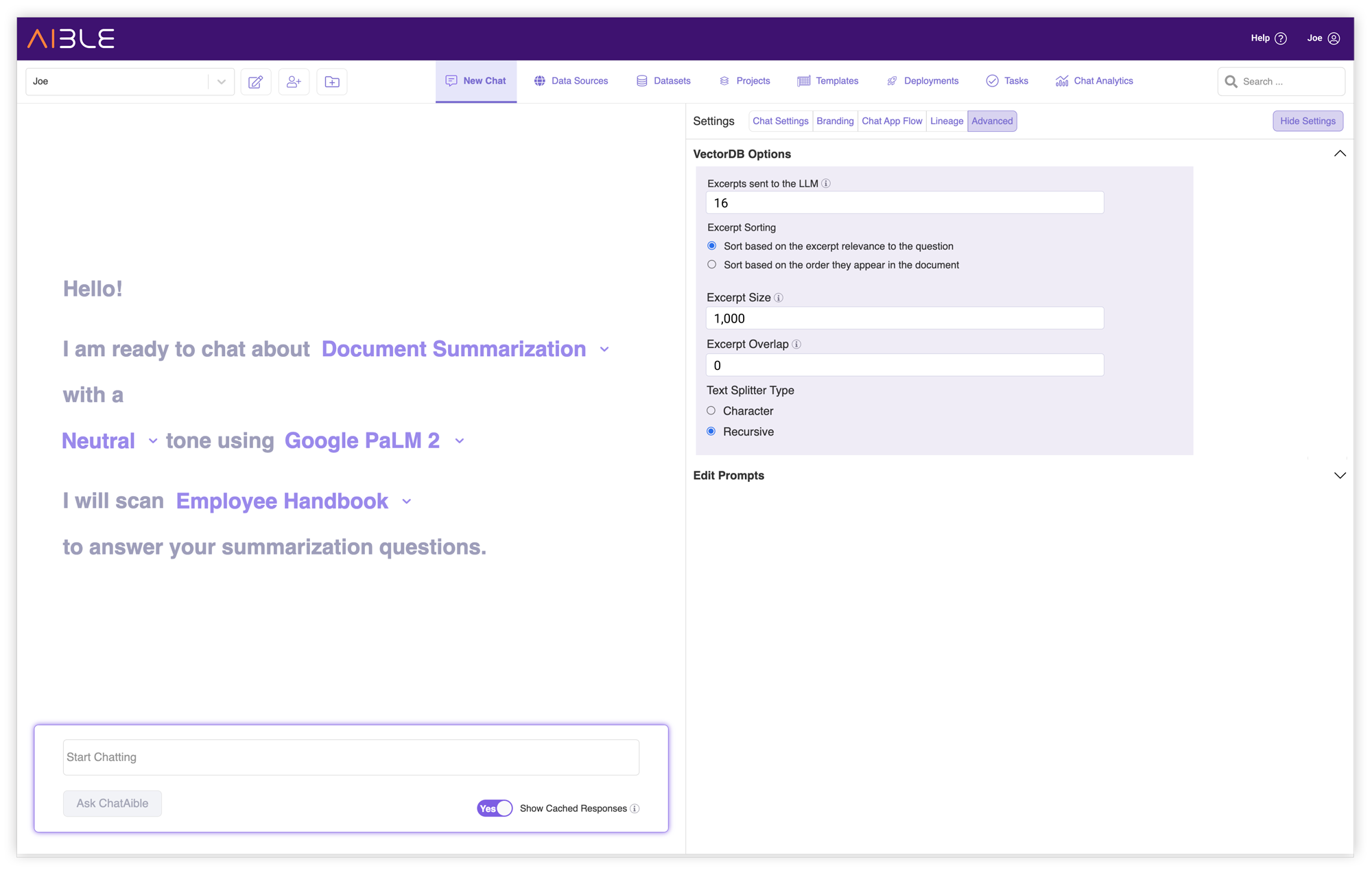
Vector DB Settings per Dataset
VectorDBs are a key technology for most unstructured GenAI use cases. Based on an user’s question, a VectorDB helps retrieve the most relevant document snippets that can be used by the GenAI to answer the user’s question. The problem is that most VectorDBs are configured independent of the actual use case. Examples of such settings include the length of individual snippets and the number of snippets returned by the VectorDB.
For example, if you are trying to answer questions based on a directory, you would want the VectorDB to return short snippets. This is because adjacent entries in a directory (think old school yellow books for example) do not contain relevant information. At the same time, because a directory might contain many examples related to the question, you want to return many individual snippets. The settings would be very different if you are trying to answer questions based on a news article. Here the snippets should be longer because adjacent sections of text typically contain related information but we may only have room for fewer snippets so as to not go over the constraints of the context window.
Aible runs a completely serverless VectorDB such that there can be different available-on-demand VectorDBs for individual use cases. This allows Aible users to use the right settings for each use case without affecting other use cases. Aible chat templates incorporate the best practices VectorDB settings for common use cases.
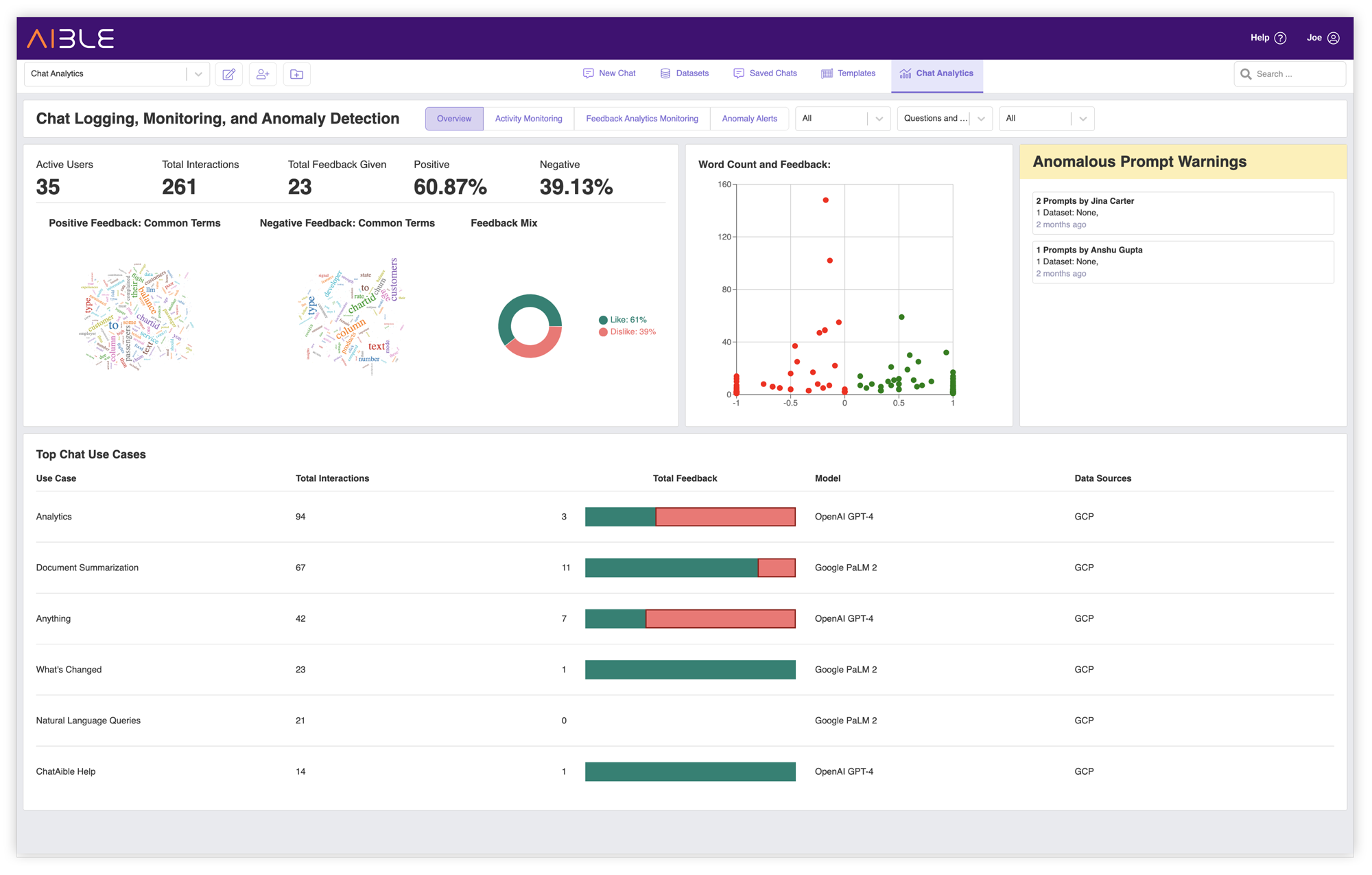
Chat Analytics & Anomaly Detection
Aible automatically monitors every chat interaction across clouds, models, users, use cases, etc. in a consistent way. All monitoring data is stored in the customer’s own Virtual Private Cloud (VPC). Aible automatically detects the most popular use cases, datasets, etc. and highlights underlying patterns of positive and negative feedback. Aible also auto-detects ‘anomalous prompts’ - cases where a user's prompts significantly differ from those of other users.
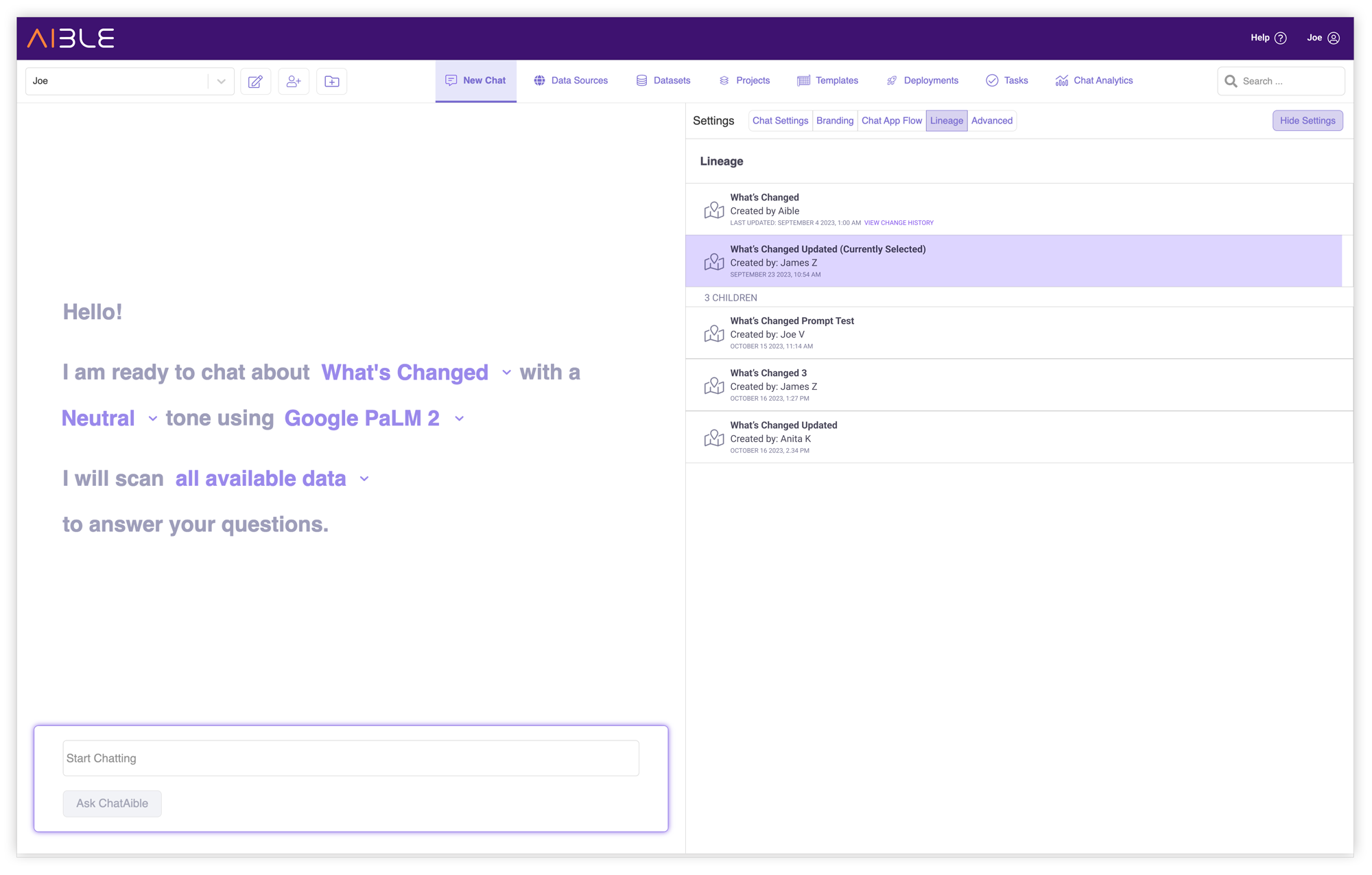
Chat Template Lineage
Aible Chat Templates encode best practices such as Large Language Model (LLM) settings, VectorDB settings, Prompt Augmentation, grounding instructions, etc. Aible includes default chat templates for common use cases such as document summarization, analytics, NLQ, etc. But organizations often want to customize the chat templates for the unique needs of their use cases. For example, we may create a Salesforce Lead Analytics chat template derived from the primary
When underlying technology such as LLMs change, we need to update the Chat Templates to compensate for the change so that the use case works better than before, based on the updated tech. The Prompt Augmentation and recommended settings for GPT-3.5 are significantly different from those for GPT-4 for example. So when GPT-4 was released we had to update each of the relevant chat templates to make them work with GPT-4 as well. With the Aible Chat Template Lineage mechanism, we need to typically make such changes only once in the original parent template and all use-case-specific child templates derived from the parent immediately inherit all the improvements and can then start benefiting from the new technology. In the absence of this lineage technology IT organizations will find it really difficult to manually keep use cases updated as underlying technology changes.