


 Overview:
Overview:
Enterprises are increasing their focus on Small Language Models (SLMs) as the preferred solution for Enterprise Generative AI. There are several reasons for this including specificity, security, cost, and speed.
Specificity:
Large Language Models (LLMs) are trained on vast volumes of data from the open Internet and can respond to a wide variety of user requests - from cookie recipes to poems. But they don’t have access to the private data of the enterprise and don’t understand the unique terminology of each enterprise. Major enterprises always customize their enterprise systems like Salesforce, Oracle, etc. because they have unique ways of doing and naming things. In the world of generative AI, this remains a problem because LLMs trained on general data cannot understand enterprise-specific data. There are a few ways to solve this with LLMs, but all of them are expensive. First, you can provide a lot of enterprise-specific context in the prompts, but this gets expensive at high volumes of requests. Second, you can fine-tune the models to specialize on the enterprises’ unique data and context, but that can be quite expensive for large models. Gartner, for example, estimates that it costs more than $5 million to fine-tune a model. Third, you can train your own LLM, but that is cost-prohibitive or complete overkill for most companies.
Small models are less generalizable than LLMs, so they can’t perform as wide a variety of tasks. However, small models are less expensive to fine-tune than LLMs. At the Gartner Data and Analytics Summit, Verizon talked about how they were able to fine tune a SLM for $90 of compute cost in less than 7 days. End users actually preferred the output of the fine-tuned SLM to that of a much bigger and more expensive LLM. Thus, fine-tuned SLMs are an excellent solution for enterprises’ need for customization.
Security:
LLMs are essentially a resource shared across many customers. While the LLM providers contractually agree to never look at customer data, they technically could do so. From a security perspective, enterprise customers can run SLMs completely under their own control while they effectively have to share LLMs with other customers. To fine-tune large models like GPT-4, enterprises have to provide OpenAI with the necessary data, while they can easily fine-tune SLMs even on a laptop. This has led to a lot of interest in SLMs from a security perspective.
Cost and speed:
The cost and speed components are obvious. Larger models simply cost more and take more time to operate. Smaller models have the potential to save significant costs here. However, there is one key problem that makes SLMs on servers significantly more expensive than hosted LLMs. SLMs are more specialized and thus a given SLM gets fewer requests than a more generalized LLM. Think of a Swiss army knife compared to individual tools comprising such a knife. The Swiss army knife gets used when its user needs any of the tools, while each of the individual tools would share only part of that usage demand. When SLMs are placed on servers, each server spends a lot of time waiting for requests and due to that waste, the operating cost of SLMs on servers is actually higher than the effective operating cost of a shared LLM.
Serverless to the rescue:
The original promise of the cloud was that we would buy compute resources by usage just like we buy electricity from the utilities. In reality though, using servers on the cloud is like renting electricity generators - you still need to pay the rent whether or not you are actually actively using it. For scarce resources like servers with GPUs, the problem becomes worse. Because users often need to wait for hours for such a server to become available, Data Scientists and IT departments regularly ‘reserve’ such servers, essentially renting the server even though they are not actively using it. Serverless is a common technique to securely share the same server across multiple enterprises. Such ‘serverless resources’ come up almost instantly to respond to customer requests, charge by the second for the usage, and don’t retain any information between customer requests.
NVIDIA DGX Cloud offers serverless access to GPU instances spanning across multiple regions. We were extremely intrigued by this, because serverless techniques should work extremely well on GPUs, and due to the relative shortage of GPUs, anything that improves the utilization rates of existing GPUs should have significant business impact.
But, there were three key concerns that we had to navigate.
First, DGX Cloud spans across resources on multiple clouds. Thus, customers were very concerned about security risks and data egress costs. Aible solved this by using its serverless vectorDB for unstructured data and the serverless Aible Information Model (AIM) for structured data in the cloud where the source data already was, while running the SLMs on DGX Cloud. This way the data remains where it is and only the necessary snippets move across clouds, if necessary. The snippets are of course much smaller data volumes than the full documents would be, and this reduces data egress costs and risks. AIM can further k-anonymize and mask such transmitted data for structured data sources. This addresses the security and data residency concerns of customers.
Second, nowadays customers are concerned about the availability of on-demand GPUs. Now, this is a concern that will become moot as DGX Cloud ramps up, but for now it is a realistic concern. Because we support the exact same models on the cloud providers own CPU-based serverless offerings, Aible can simply fall back to CPU-based serverless when GPUs are not available. In fact, when GPUs are in short supply, Aible can send batch mode and agentic requests to serverless CPUs while prioritizing latency-sensitive applications like chat to serverless GPUs. Think of it as Uber where if Uber Black cars are not available, it may offer you an UberX sooner. Finally, customers can also choose to use reserved clusters on their cloud instances or even on-prem clusters and Aible can use DGX Cloud to put the workload on such servers if latency is an absolute concern. (This of course reduces the TCO benefits of serverless because using reserved clusters leads to wasted compute resources whenever the customer that did the reserving has no demand.)
Third, most data scientists and IT teams are not used to dealing with serverless systems. So, it would take some time for such experts to get trained on DGX Cloud. However, Aible abstracts away all of the complexity there. End-users do not need to write any code specific to DGX Cloud, to gain the benefits of the AI platform.
Unfortunately GPUs, or even more recent CPUs, are not yet available in production on the major serverless platforms like Google Cloud Run, AWS Lambda, or Azure Functions. So Aible had previously benchmarked LLMs, demonstrating that SLMs, and even end-to-end Retrieval Augmented Generation (RAG) use cases can be run serverless on CPUs at an 11X to 55X TCO reduction. The benefits of running SLMs on DGX Cloud on major cloud serverless platforms?
40X-200X lower TCO even while only processing one request at a time (the TCO would be even lower while processing multiple requests in parallel):

The serverless on CPU and Dedicated Servers numbers are from a prior analysis that can be found in this full benchmark report for additional context.
We also ran different size workloads to test the end-to-end performance of the system. Note, each of these durations start from when the user asks the question to the point when the response is completed and includes both the time for the serverless vectorDB running in the native cloud on CPUs and the language model running on DGX Cloud with GPUs.
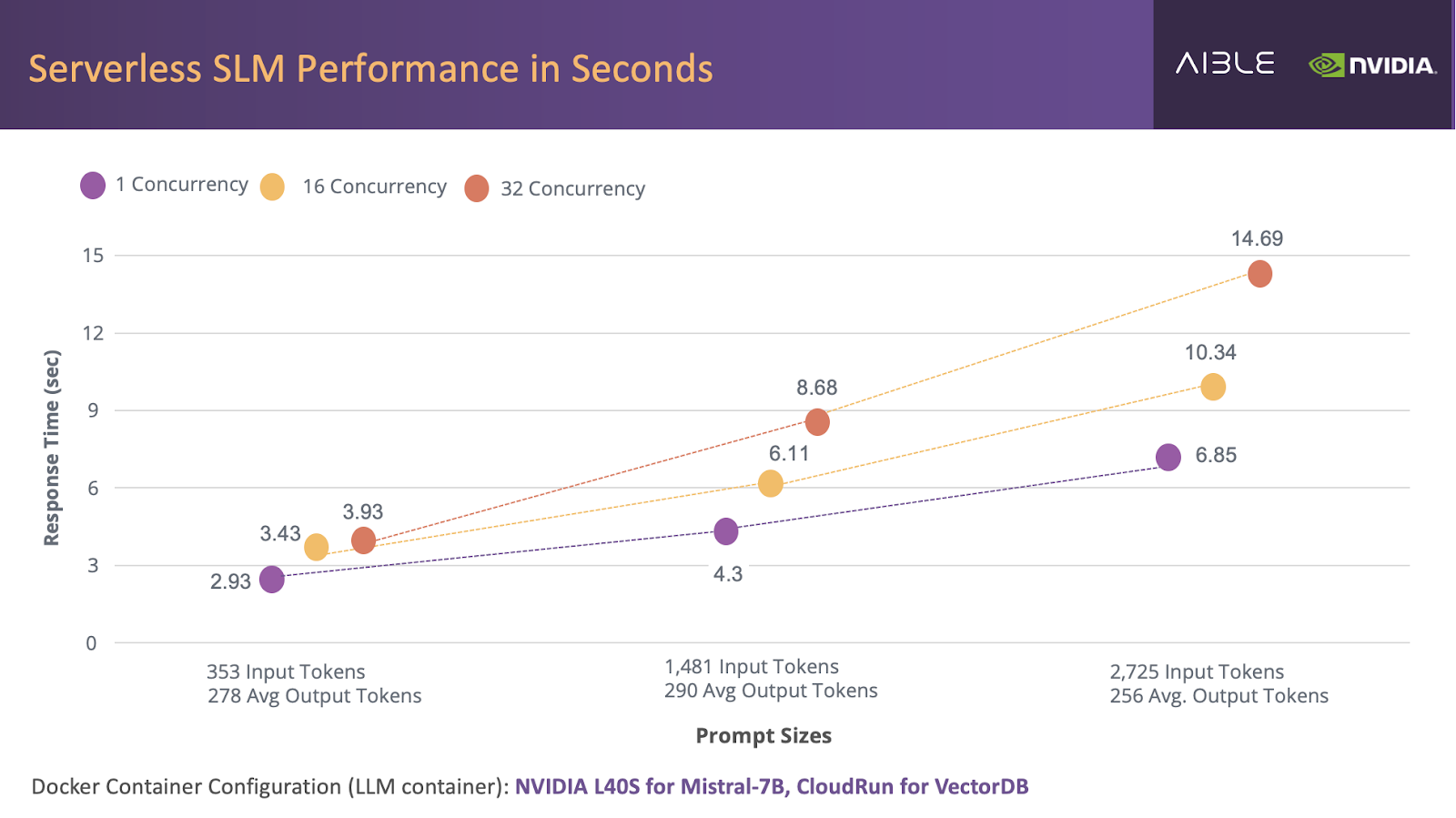
At higher concurrencies the GPU handles more requests in parallel, so each request takes a little longer but can be significantly less expensive to run. The TCO reductions calculated above was at just 1 concurrency. At higher volumes, if customers are willing to wait a few seconds longer for the response, the TCO can be significantly lowered further by increasing the concurrency level. Once again, the DGX Cloud architecture and concurrency support enables customers to go for lower cost of operations where speed is less of a concern by increasing the concurrency or the number of requests a GPU can handle in parallel. At the same time, they can achieve extremely high performance by processing just one request at a time (end-to-end response times for 2.9 seconds to 3.9 seconds) while still maintaining a 40X to 200X TCO reduction. By observing the performance characteristics across customers, Aible can dial in the optimal concurrency for each model and average prompt length.
SLMs and end-to-end RAG on serverless is the most cost-effective, fast, secure, and customizable option available to enterprises today. DGX Cloud further enhances the TCO and performance of end-to-end RAG using SLMs on serverless and offers an easy way for customers to balance performance and cost.